MG-Verilog: Multi-grained Dataset Towards Enhanced LLM-assisted Verilog Generation
Received the Best Paper Award at the inaugural IEEE LAD 2024 workshop on LLM-Aided Design.
Research Scientist @ NVIDIA
I design efficient learning algorithms for large language models, with a focus on inference calibration, adaptive tuning, and human-in-the-loop hardware design. My work bridges LLM foundations with practical deployment on data- and compute-constrained platforms.
Currently, I'm exploring on-the-fly inference upgrades for foundation models and co-designing AI accelerators with LLM assistance.

Recent milestones, publications, and recognitions.
Received the Best Paper Award at the inaugural IEEE LAD 2024 workshop on LLM-Aided Design.
Our attention calibration framework for LLMs has been accepted to ICML 2024.
Layer-wise compression and adaptive tuning techniques for on-device LLM adaptation accepted by DAC 2024.
Our LLM-driven accelerator design framework has been accepted by ICCAD 2023.
Won 2nd place in the University Demo Best Demonstration Award at DAC 2023.
Modularized multilingual ASR system accepted by ICML 2023.
Few-shot ViT tuning framework accepted by CVPR 2023.
Efficiency boosting framework for tiny neural networks accepted by DAC 2023.
I study how to make large language models adaptable, efficient, and dependable in real-world settings. My research spans three pillars:
Previously, I earned my Ph.D. in Computer Science from Georgia Tech, advised by Prof. Yingyan (Celine) Lin. I also hold an M.S. from Columbia University and a B.Eng. from Zhejiang University, and I have collaborated with MIT-IBM Watson AI Lab.
* denotes equal contribution
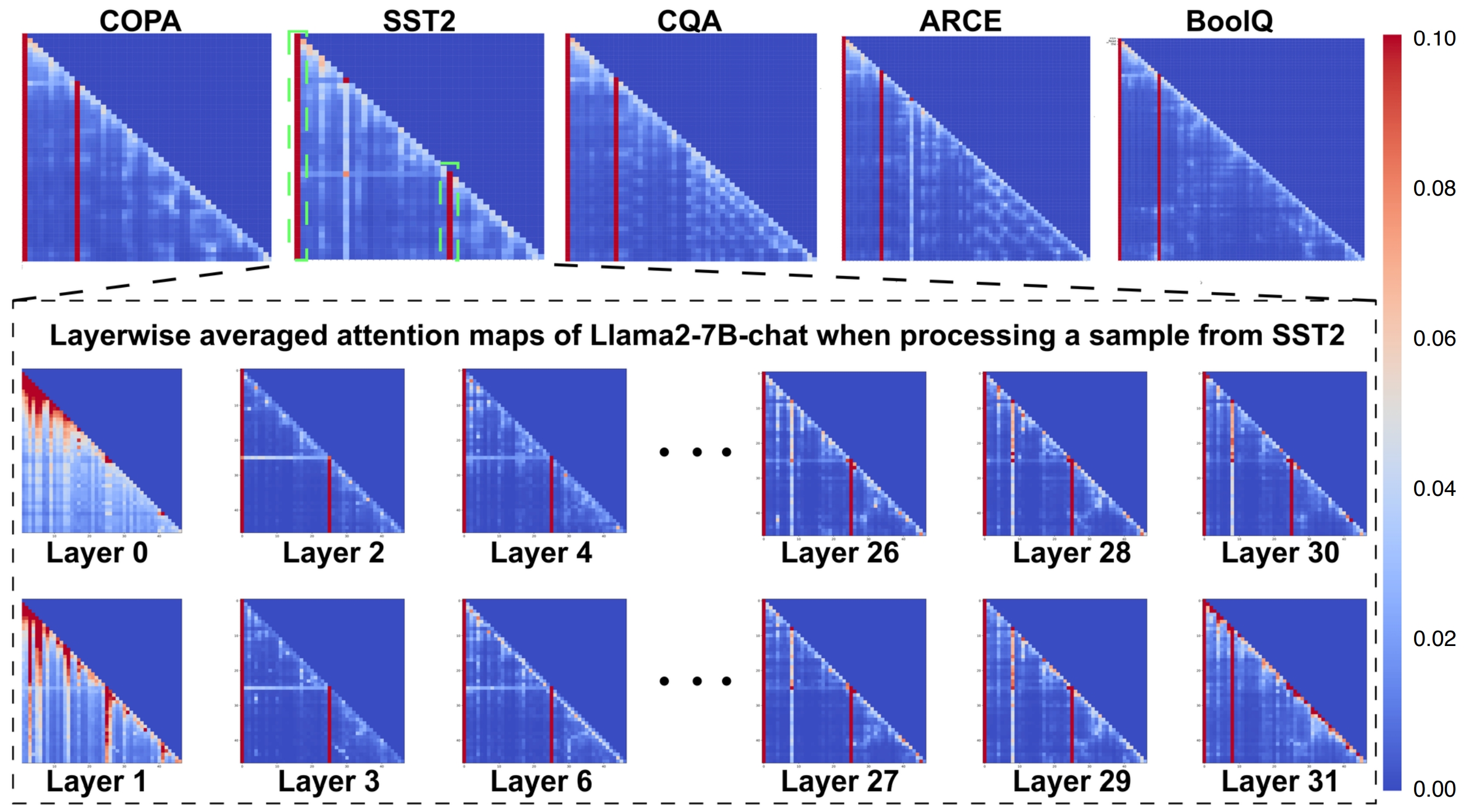
A systematic study of attention sink behaviors in LLMs paired with an inference-time calibration method.
Paper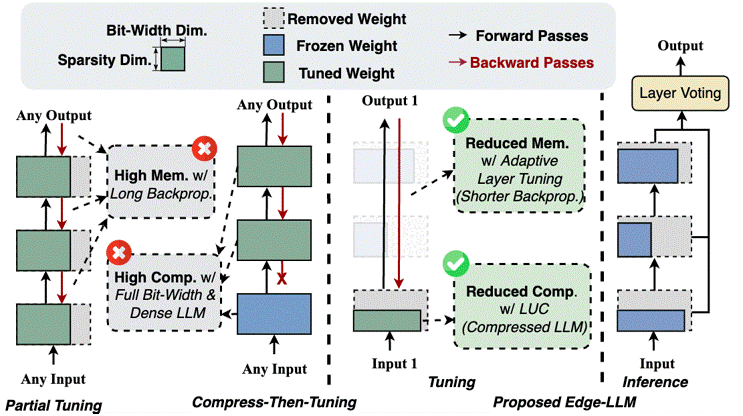
Compression-aware fine-tuning that unlocks on-device LLM adaptation with minimal hardware overhead.
Paper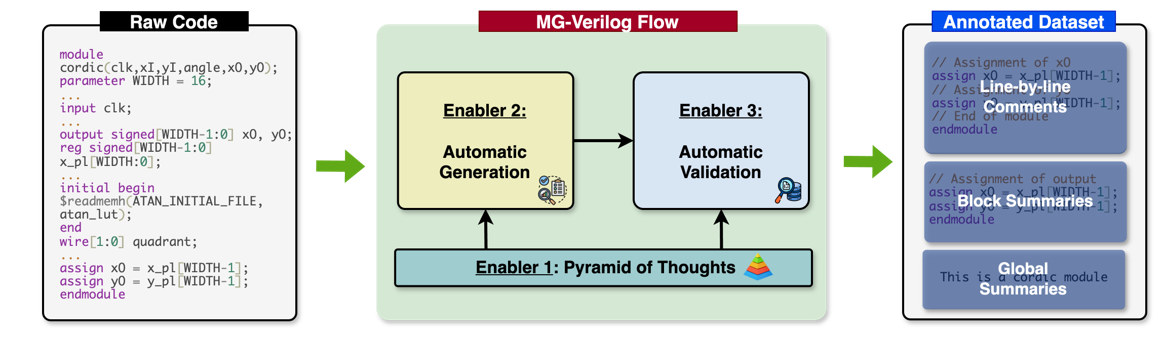
The first multi-granularity Verilog dataset enabling precise LLM-guided hardware code generation.
Paper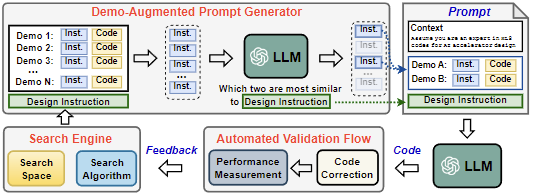
Human-in-the-loop workflows that translate natural language into accelerator design artifacts.
Paper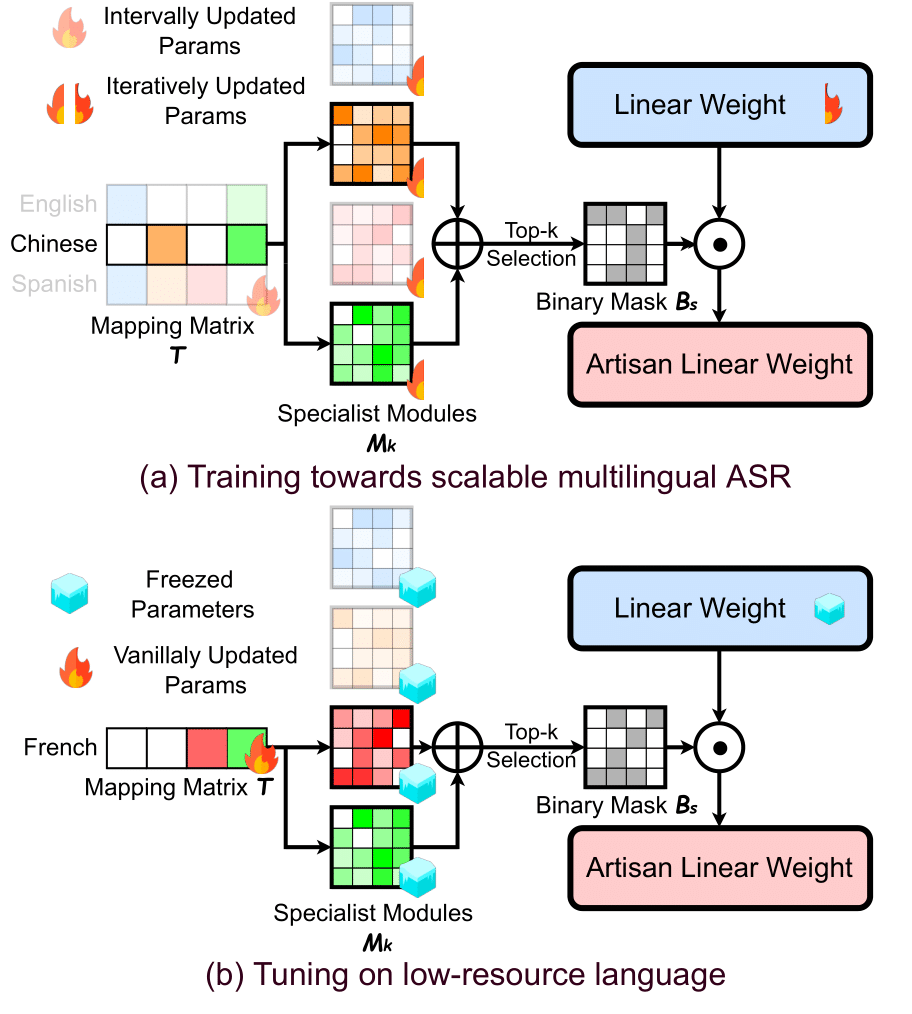
A modular ASR architecture that balances multilingual performance and low-resource specialization.
Paper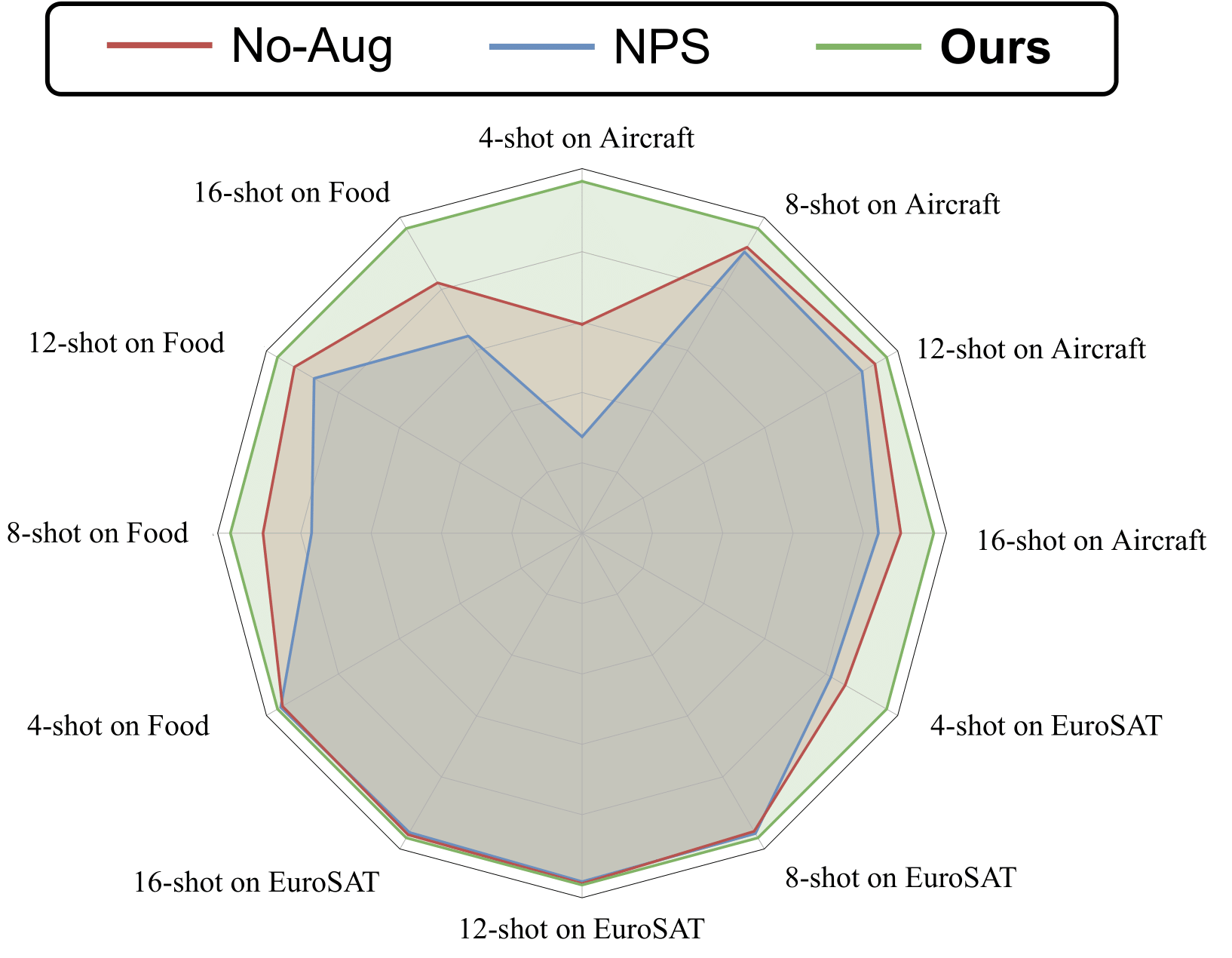
Integrating attention-aware data augmentation to amplify few-shot ViT tuning effectiveness.
Paper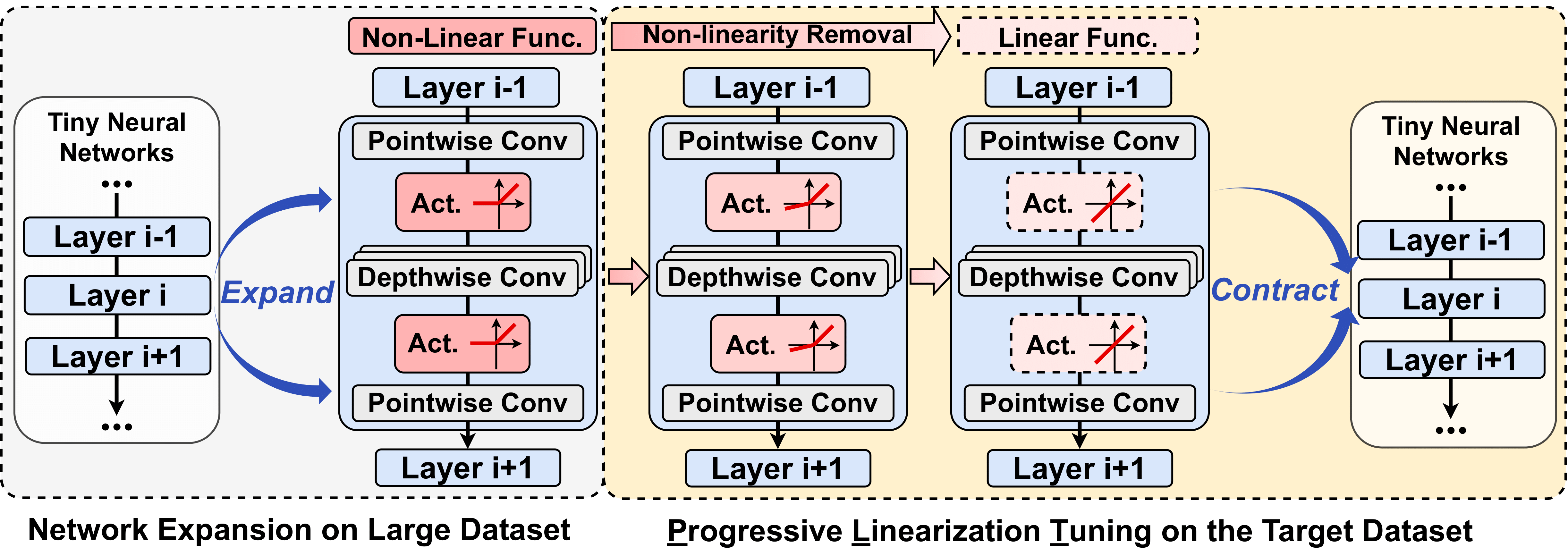
A blueprint for uplifting compact neural networks via expansion-then-contraction strategies.
Paper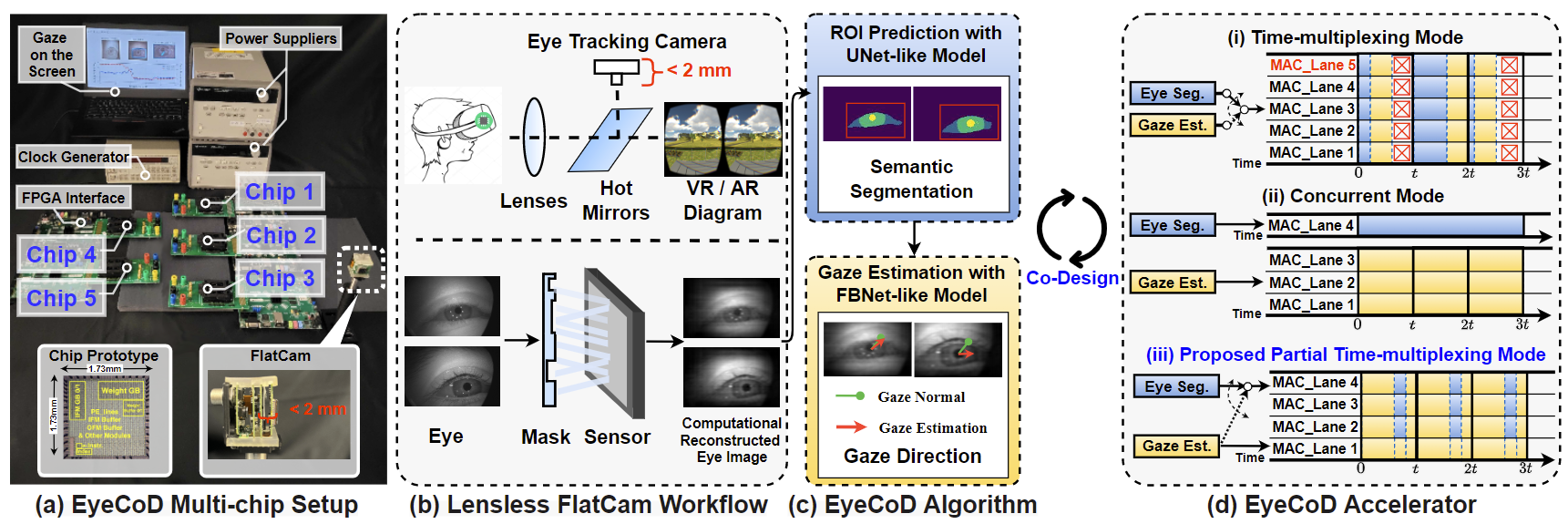
A compact lensless eye-tracking system achieving high throughput through algorithm-hardware co-design.
Paper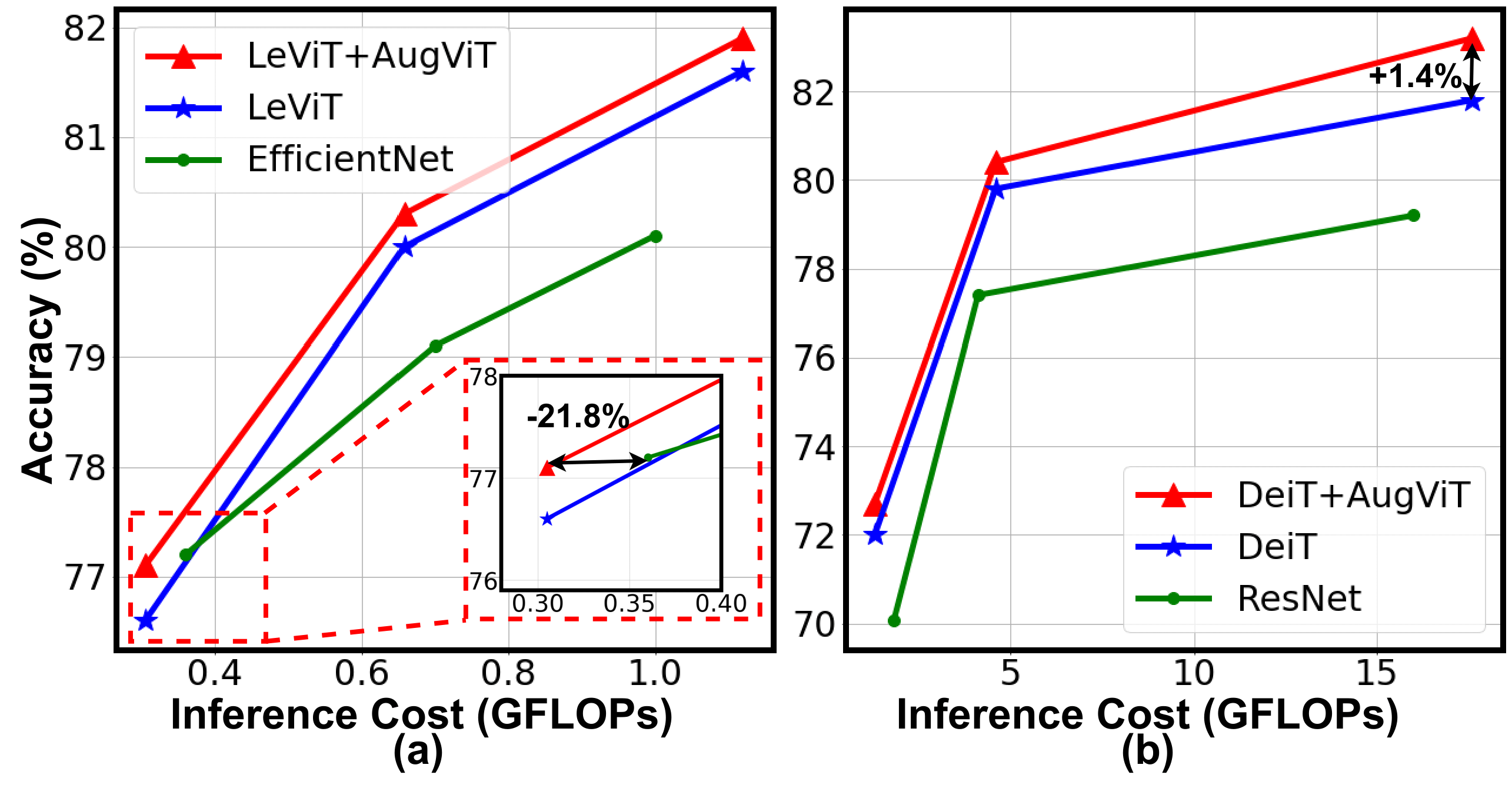
An attention-aware augmentation framework that consistently lifts ViT accuracy across hardware tiers.
Paper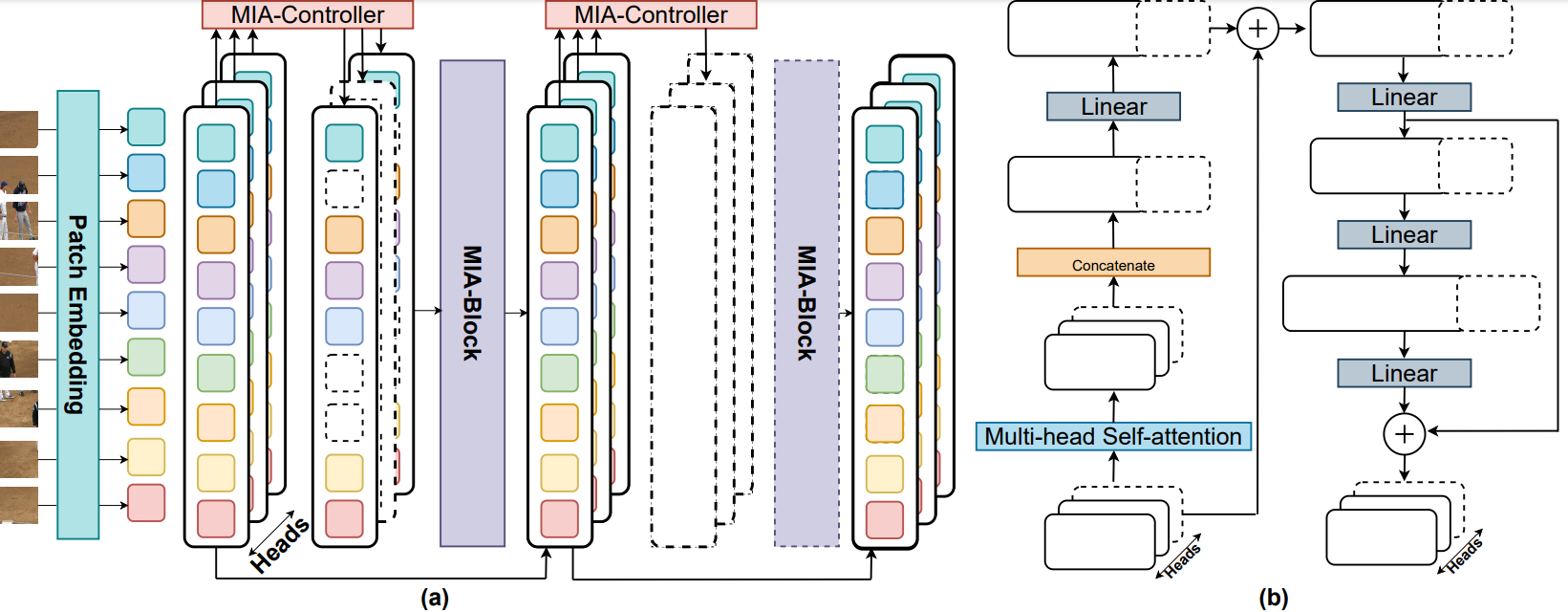
A multi-grained input-adaptive ViT that dynamically adjusts depth, heads, and tokens.
Paper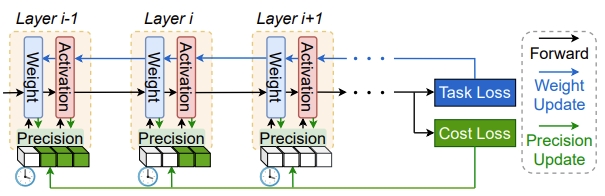
Temporal and spatial precision scheduling for DNN training that optimizes accuracy-efficiency trade-offs.
PaperICLR 2023, NeurIPS 2022–2023, ICML 2023, CVPR 2023, AAAI 2022, AICAS 2022.
MICRO 2023 Artifact Evaluation Committee.